
Web scraping has become an essential skill for anyone working with data, allowing for the extraction of valuable information from websites. Google Sheets provides a powerful tool for this purpose: the IMPORTXML function.
XPath, a query language for selecting nodes from XML documents, enhances IMPORTXML into a versatile tool for extracting specific data from web pages.
In fact, I posted the below LinkedIn post and, based on the activity, figured a longer form post was warranted.
This article provides a comprehensive guide to using XPath with IMPORTXML in Google Sheets, covering implementation steps, advanced techniques, and troubleshooting strategies that can be applied for SEO and an infinite number of other applications.
Understanding XML and HTML
Before diving into the specifics of IMPORTXML and XPath, it’s important to understand the difference between XML and HTML.
While both are markup languages with similar structures, they serve different purposes. XML (Extensible Markup Language) is primarily used for transporting and storing data, while HTML (HyperText Markup Language) is used to display data in a web browser.
HTML uses predefined tags (like<p> for paragraphs and <h1> for headings) to structure content, while XML allows users to define their own tags. This flexibility makes XML suitable for representing various data structures.
Understanding the hierarchical structure of HTML is crucial for using XPath effectively. HTML elements are organized like a tree, with a root element (<html>) branching into child elements (like<head>and <body>), which can further have their own child elements. Each element can have attributes that provide additional information about the element.
Implementation Steps
Here’s a step-by-step guide to using XPath with IMPORTXML:
- Identify a web page containing the desired data: Start by finding the web page with the information you want to extract. This could be anything from product prices on an e-commerce site to news headlines from a blog.
- Use browser developer tools to inspect the page structure: Open the web page in your browser (like Chrome or Firefox) and right-click on the element containing the data you want. Select “Inspect” or “Inspect Element” to open the developer tools. This will allow you to see the underlying HTML structure of the page.
- Formulate an XPath expression to isolate the relevant nodes: In the developer tools, locate the specific HTML element or elements that contain the data you want to extract. Right-click on the element in the HTML code and choose “Copy” -> “Copy full XPath”. This will give you the XPath expression that points to that specific element.
- Use the
IMPORTXMLfunction in Google Sheets: In your Google Sheet, type the following formula into a cell:=IMPORTXML("URL", "XPath", locale). Replace “URL” with the URL of the web page, “XPath” with the XPath expression you copied in the previous step, and “locale” with an optional argument specifying the language and region for parsing the data (e.g., “en_US”). For example, to extract the title of a web page, the XPath expression would be//title, and the formula would look like this:=IMPORTXML("https://www.example.com", "//title"). - Extract multiple data points with additional
IMPORTXMLcalls: You can use multipleIMPORTXMLfunctions to extract different pieces of information from the same web page. Simply repeat step 4 with different XPath expressions for each data point you want to extract. For example, to get the current air quality index for San Francisco, you could use the following formula: =IMPORTXML(“https://weather.com/en-GB/weather/today/l/69bedc6a5b6e977993fb3e5344e3c06d8bc36a1fb6754c3ddfb5310a3c6d6c87″,”//html/body/div/main/div/aside/div/div/section/div/div/div/svg/text”) - Understand absolute and relative XPath selectors: Absolute XPath selectors start with a single forward slash
/and specify the complete path from the root of the document to the desired element. Relative XPath selectors start with two forward slashes//and select elements anywhere in the document that match the specified criteria. Relative XPath selectors are generally preferred because they are more resistant to changes in the website’s structure. - Import XML tables from web pages: You can import entire tables from web pages using
IMPORTXML. To do this, inspect the table element in the developer tools and identify the<tr></tr>tags that represent table rows. The XPath expression//table/tbody/*can be used to import the nth table on the page, where n is the table’s position in the HTML code. - Verify and adjust your XPath expressions: Websites can change their structure, which may break your XPath expressions. If you encounter errors or empty returns, revisit the website and inspect the element again to update your XPath expression accordingly.
Constructing Complex XPath Expressions
While basic XPath expressions can extract simple data, more complex expressions are needed to retrieve deeper or more specific information. Here are some techniques for constructing complex XPath expressions:
- Utilizing Functions: XPath functions can be used to manipulate strings, numbers, and other data types. Some common functions include
contains(),text(),starts-with(), andstring-length(). For example,//span[contains(text(), 'example')]selects all<span>elements that contain the text “example”. Another useful function isnormalize-space(), which removes leading and trailing whitespace from a string and replaces sequences of whitespace characters with a single space. This can be helpful when dealing with HTML elements that contain inconsistent whitespace. - Field References: You can use field references (e.g.,
%FieldName%) within XPath expressions to dynamically change the value being searched for. This can be useful when you want to create a more flexible XPath expression that can be adapted to different situations. - Chaining Expressions: You can chain multiple XPath expressions together to navigate through the document hierarchy. For example,
//div[@class='container']//aselects all<a>elements with anhrefattribute that are descendants of a<div>element with the class “container”. - Combining Axes: XPath axes define the relationship between nodes in the document. Some common axes include
ancestor,child,following,preceding, andself. For example,//div[@id='content']/child::pselects all<p>elements that are children of the<div>element with the id “content”. - Using Predicates: Predicates are conditions enclosed in square brackets that allow you to filter elements based on their attributes or position. For example,
//a[@class='link']selects all<a>elements with the class attribute “link”. You can also use relational operators like=,!=,<,>,<=, and>=within predicates to further refine your selection. For example, to select all links on a page that point to a specific domain, you could use an expression like this://a[contains(@href, 'example.com')]
| Relational Operators | Function |
|---|---|
| = | Equal |
| != | Unequal |
| < | Less than; masking required within XSLT (<) |
| > | Greater than; masking within XSLT (>) is recommended |
| <= | Less than or equal; masking required within XSLT (<) |
| >= | Greater than or equal; Masking within XSLT (>) recommended |
You can also combine predicates using and and or operators. For example, //div[(contains(@class,'toc')][@attribute="value")] selects all <div> elements that have a class attribute containing “toc” and also have a specific attribute with a specific value.
XPath SEO Tactics
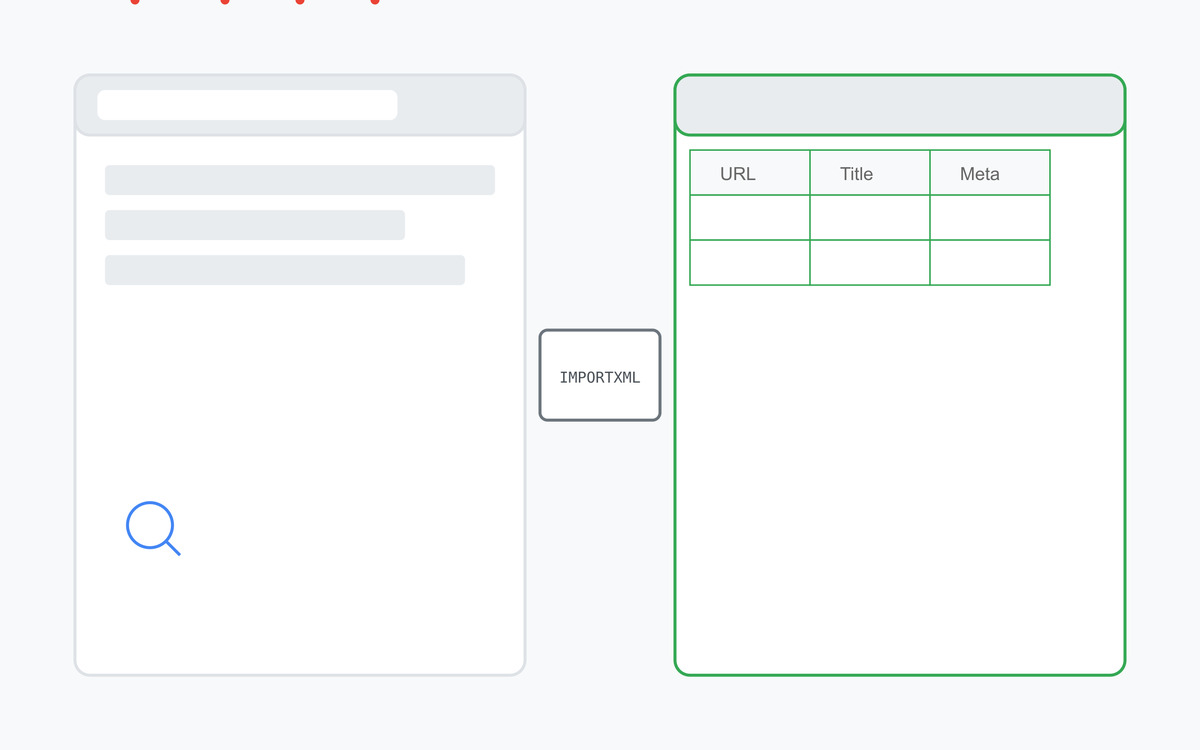
IMPORTXML, when combined with XPath, can be a powerful tool for SEO professionals. Here’s how you can apply it to enhance your SEO efforts:
1. On-page SEO analysis:
- Extract meta tags: Quickly gather meta titles and descriptions from a list of URLs to analyze their optimization and identify areas for improvement. Use formulas like
=IMPORTXML(A2,"//title/text()")for titles and=IMPORTXML(A2,"//meta[@name='description']/@content")for descriptions . This allows you to check for keyword inclusion, length, and overall effectiveness. - Identify heading structure: Extract heading tags (H1, H2, etc.) to ensure proper hierarchy and keyword usage within the page content. This can be done with formulas like
=IMPORTXML(A2, "//h1"). - Analyze internal linking: Extract all links (
//a/@href) from a page to understand the internal linking structure and identify potential improvements for better crawlability and user experience . - Check for structured data: Use XPath to extract schema markup and validate its implementation to ensure search engines understand the content on your pages.
2. Off-page SEO analysis:
- Scrape competitor data: Analyze competitor websites to understand their on-page optimization strategies, content structure, and keyword targeting.
- Identify backlink opportunities: Extract links from relevant websites to identify potential backlink opportunities.
- Track rankings: Monitor keyword rankings by scraping SERP data and extracting ranking positions for your website and competitors.
- Analyze competitor’s sitemaps: Extract data from competitor XML sitemaps to understand their website structure, content priorities, and last updated dates. This can provide valuable insights for content strategy and competitive analysis.
- Extract social media data: Extract social media metrics like share counts, likes, and comments from a list of URLs to analyze content performance and identify social media trends. This can be achieved by scraping social media APIs or using third-party tools that provide this data in a structured format.
3. Technical SEO:
- Check for broken links: Extract all links on a page and use
IMPORTXMLwith theHTTP status codescript to identify broken links (404 errors) . - Analyze sitemaps: Extract data from XML sitemaps to understand the structure of a website and identify potential indexing issues.
- Monitor website speed: Use
IMPORTXMLto extract data from website speed test tools to track performance and identify areas for improvement. - Track internal link changes: Monitor changes in internal linking by periodically scraping pages and comparing the extracted links to previous versions. This can help identify broken links, new internal links, or changes in anchor text.
- Analyze hreflang tags: Extract hreflang tags from a list of URLs to ensure proper internationalization and avoid duplicate content issues. This can be particularly useful for websites targeting multiple languages or regions.
- Monitor website accessibility: Extract accessibility data, such as alt text for images or ARIA attributes, to identify potential accessibility issues and improve the user experience for people with disabilities.
4. Content analysis:
-
- Identify thin content: Extract word counts from a list of URLs to identify pages with thin content that may need improvement. This can be done by combining
IMPORTXMLwith other functions likeIMPORTDATAto fetch the page content and then calculate the word count. This helps prioritize content optimization efforts - Extract content: Extract specific elements from web pages, such as product descriptions, reviews, or articles, to analyze content quality, identify trends, or gather data for content creation.
- Identify content gaps: Analyze competitor content to identify topics and keywords they are targeting that you might be missing.
- Track keyword rankings in image search: Extract image URLs and alt text from a list of pages to monitor keyword rankings in image search results. This can help optimize images for better visibility and drive traffic from image search.
- Identify thin content: Extract word counts from a list of URLs to identify pages with thin content that may need improvement. This can be done by combining
Example:
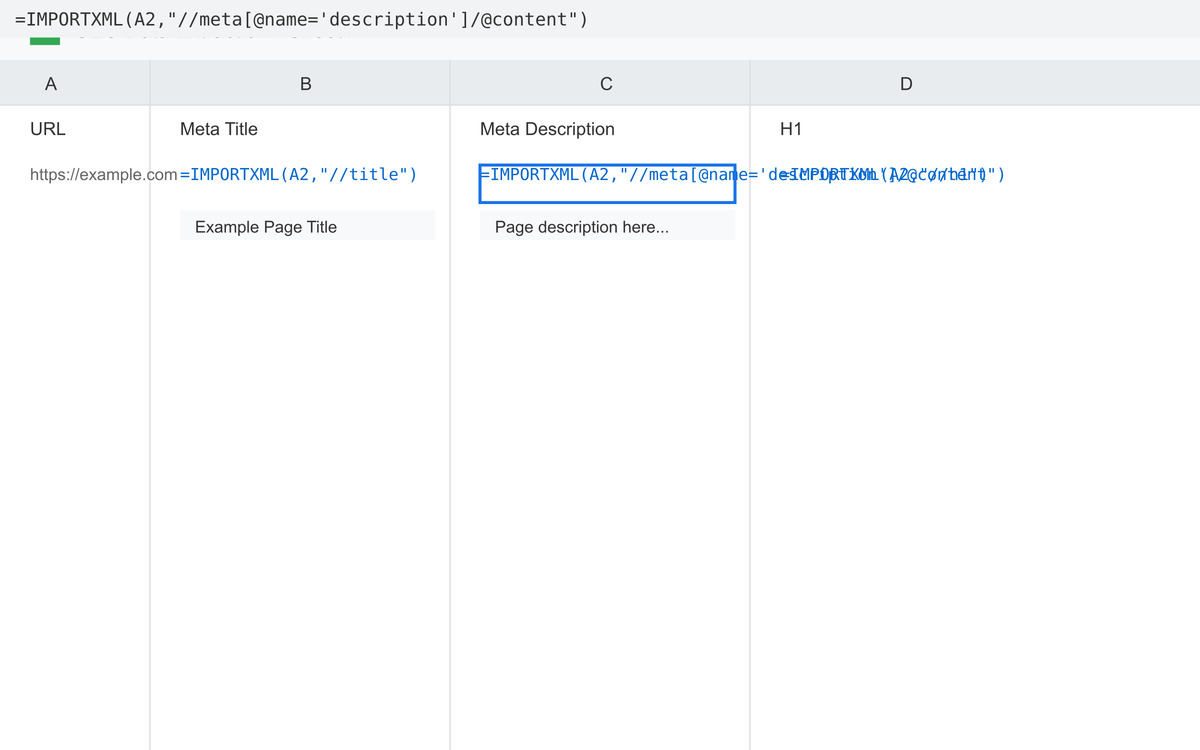
Let’s say you want to analyze the meta descriptions of your top 10 blog posts. You can list the URLs in column A of your Google Sheet.
In column B, use the formula =IMPORTXML(A2,"//meta[@name='description']/@content") and drag it down to extract the meta descriptions for each URL. You can then analyze the results for length, keyword usage, and clarity.
Tips for using IMPORTXML for SEO:
- Use relative XPath selectors: They are more robust to changes in website structure.
- Combine XPath expressions: Use predicates, axes, and functions to create more complex and targeted extractions.
- Verify and adjust XPath expressions: Websites can change, so regularly check your formulas and update them as needed.
- Be mindful of website limitations: Some websites may block or restrict scraping, so always respect their terms of service.
Troubleshooting IMPORTXML and XPath
Sometimes, IMPORTXML may return errors or empty results. Here are some common troubleshooting methods:
- Verify the URL: Ensure that the URL in your
IMPORTXMLfunction is correct and accessible. - Check the XPath Expression: Double-check your XPath expression for any typos or syntax errors. Use the browser’s developer tools to test your XPath expression and ensure it selects the correct element.
- Website Changes: Websites frequently update their structure, which can break your XPath expressions. Revisit the website and inspect the element again to update your XPath expression if needed.
- Dynamic Content:
IMPORTXMLmay not work with websites that load content dynamically using JavaScript. In such cases, consider alternative web scraping tools or techniques. - Website Restrictions: Some websites may block web scraping altogether or require logins for access. Check the website’s robots.txt file or terms of service to see if scraping is allowed.
Related Google Sheets Functions
In addition to IMPORTXML, Google Sheets offers other useful functions for importing data:
IMPORTDATA: This function allows you to import data from CSV (Comma Separated Values) and TSV (Tab Separated Values) files on the web. It’s a simpler alternative toIMPORTXMLwhen dealing with structured data in these formats.IMPORTFEED: This function imports data from RSS (Really Simple Syndication) and ATOM XML feeds. It’s useful for extracting information from blogs, news websites, and other sources that provide content in these formats.
Dynamic Websites and Asynchronous Content
Dynamic websites that load content asynchronously using JavaScript can be more challenging to scrape with IMPORTXML. This is becauseIMPORTXML only fetches the initial HTML content and doesn’t execute JavaScript. As a result, data loaded after the initial page load may not be accessible.
Here are some potential solutions for handling dynamic websites:
- Alternative Scraping Tools: Consider using web scraping tools like Apify, Octoparse, or ParseHub, which are designed to handle dynamic websites and JavaScript rendering.
- Google Apps Script: For more advanced scraping tasks, you can use Google Apps Script to write custom code that interacts with the web page and extracts data after JavaScript has loaded.
Another challenge with dynamic websites is the volume of data that needs to be extracted. Dynamic pages often contain a large amount of information, which can make scraping and extracting relevant data efficiently more difficult.When scraping any website, it’s crucial to respect the website’s policies. Review the terms of service, robots.txt file, and any specific scraping guidelines provided by the website.
Conclusion
IMPORTXML combined with XPath provides a powerful way to extract data from websites in Google Sheets. By understanding the implementation steps, constructing complex XPath expressions, and troubleshooting common issues, you can effectively scrape data from various websites and use it for analysis, reporting, or other purposes.
While dynamic websites may present challenges, alternative tools and techniques can be employed to overcome these limitations.By masteringIMPORTXML and XPath, you gain a valuable skill for extracting and utilizing web data within a familiar spreadsheet environment. This opens up opportunities for data analysis, automation, and informed decision-making across various domains.




